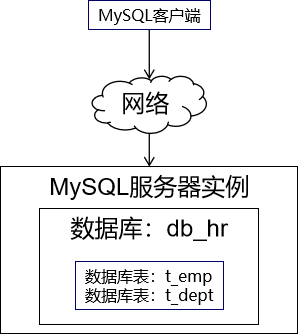
MyCat入门配置详解和常见九种数据分片算法 第一节 分库分表概述 1、为什么要拆分? ①MySQL 实例内部结构 [1]单一架构
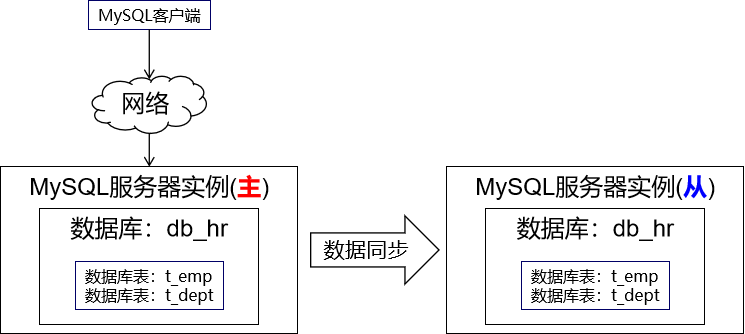
[2]复制架构 尽管搭建了复制架构,但是实际上从逻辑上来说仍然只有一个 db_hr 数据库。
②性能瓶颈 MySQL 工作过程中的性能瓶颈主要来自于下面三个方面(同等硬件条件下):
数据存储量:单表 1000 万条数据达到极限;500 万条开始性能明显下降;300 万条开始就应该考虑拆分。
I/O 瓶颈:关系型数据库以硬盘作为主要存储介质,所以必然存在 I/O 瓶颈。
访问量瓶颈:通常 MySQL 的最大连接数默认是100,最大可以达到 16384。
由此我们可以看出,对数据库进行拆分主要是出于数据量不断增加的挑战。
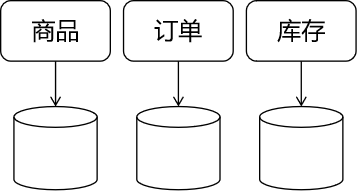
2、拆分方式 ①垂直拆分 垂直拆分是最容易想到的拆分方式。它按照项目的业务功能模块,把从属于不同模块的数据库表分散到对应的不同数据库中。
这种拆分方式的优缺点是:
优点
拆分规则明确,按照不同的功能模块或服务分配不同数据库
数据维护与定位简单
缺点
并没有解决单表数据量太大的问题
会出现跨库 join
需要对上层应用系统的代码进行重构,修改原有的事务操作
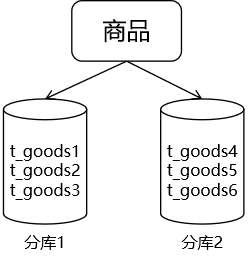
②水平拆分 针对一张数据量很大的表,把它拆分为多张表,数据分流保存到各个拆分后的数据库表中。
如果数据量继续增加,超过一个单库能够容纳的极限则需要继续分库:
这种拆分方式的优缺点评价:
只分表不分库:
同库无分布式事务问题,事务处理相对简单
同库无跨库 join 问题
表拆分后不存在超大型表的性能问题
只要拆分规则定义好,很难出现扩展性的限制,但拆分规则设定并不简单,规则一定会和业务挂钩,如根据 id、根据时间等。
既分表又分库:
异库存在分布式事务问题
异库存在跨库 join 问题
多数据源管理难度加大,代码复杂度增加
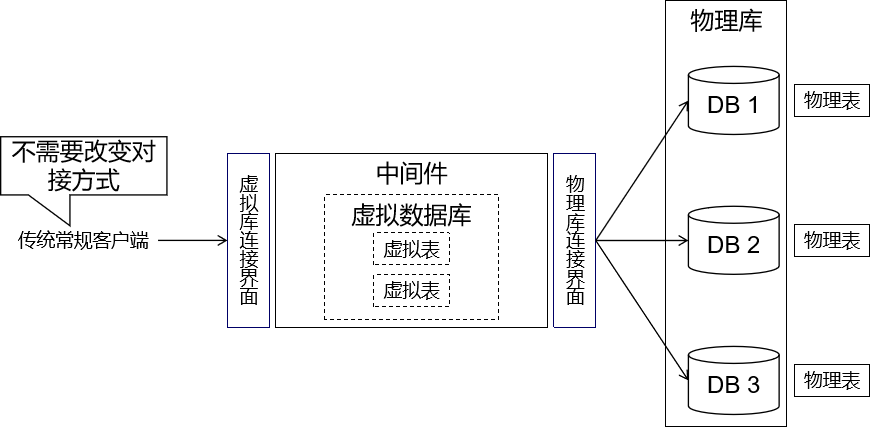
3、MyCat 简介 尽管拆分后必然要面对很多问题,但是随着数据量的增加又不得不拆分。所以我们开发的上层应用系统必须有能力对接拆分后的多个数据库。MyCat 就是帮助我们实现这一功能的数据库中间件。
MyCat 是一款数据库中间件。
对于应用程序来说完全透明:不管底层的数据如何拆分,应用只需要连接 MyCat 即可完成对数据的操作。
支持 MySQL、SQL Server、Oracle、DB2、PostgreSQL 等主流数据库。
MyCat 不存储数据 ,它只是数据的路由 。
底层拦截用户发送过来的 SQL 语句并进行分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
Mycat的特性如下:
支持SQL92标准
遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理
基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群
支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
基于Nio实现,有效管理线程,高并发问题
支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数
支持单库内部任意join,支持跨库2表join
支持通过全局表,ER关系的分片策略,实现了高效的多表join查询
支持多租户方案
支持分布式事务
支持全局序列号,解决分布式下的主键生成问题
分片规则丰富,插件化开发,易于扩展
强大的web,命令行监控
支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb
支持密码加密
支持服务降级
支持IP白名单
支持SQL黑名单、sql注入攻击拦截
支持分表(1.6以后版本)
集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0以后版本)
第二节 安装与配置 1、获取 MyCat 程序 ①方式一 访问这个地址下载:https://codeload.github.com/MyCATApache/Mycat-Server/zip/Mycat-server-1675-release
②方式二 由老师发给你。
2、解压 MyCat 压缩包
3、使用 IDEA 打开
4、配置 schema.xml 从这里开始,我们就是在初步搭建 MyCat 服务器。我们想要初步实现的目标:
MyCat 中配置虚拟数据库、虚拟数据库表,物理库和物理表暂时不拆分
启动 MyCat
使用客户端连接到 MyCat
而让 MyCat 连接物理库、配置虚拟库、虚拟表都需要在 schema.xml 中配置。
①配置文件位置
②告诉 MyCat 如何连接物理库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <dataHost name ="virtual-host-hello" maxCon ="1000" minCon ="10" balance ="0" writeType ="0" dbType ="mysql" dbDriver ="jdbc" switchType ="1" slaveThreshold ="100" > <heartbeat > select user()</heartbeat > <writeHost host ="hostM1" url ="jdbc:mysql://localhost:3306" user ="root" password ="root" /> </dataHost >
③配置 dataNode 1 2 3 4 5 6 7 <dataNode name ="data-node-hello" dataHost ="virtual-host-hello" database ="db_hr" />
④创建虚拟库和虚拟表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <schema name ="virtual-db-hello" checkSQLschema ="true" sqlMaxLimit ="100" > <table name ="virtual_t_emp" primaryKey ="emp_id" dataNode ="data-node-hello" autoIncrement ="true" fetchStoreNodeByJdbc ="true" subTables ="t_emp" /> </schema >
5、配置 server.xml ①配置文件位置
②配置 MyCat 自身的连接信息 1 2 3 4 5 6 7 8 9 10 <user name ="myCat" > <property name ="password" > hello</property > <property name ="schemas" > virtual-db-hello</property > </user >
6、启动 MyCat ①找到 MyCat 启动类
②配置 JVM 参数
指定 MYCAT_HOME:这个参数是需要指定 MyCat 工程的 src/main 目录的完整路径。
指定直接内存大小:如果 512M 不够,那就指定 1024M。
-DMYCAT_HOME=D:\idea2019workspace\mycat210722\src\main
③运行程序
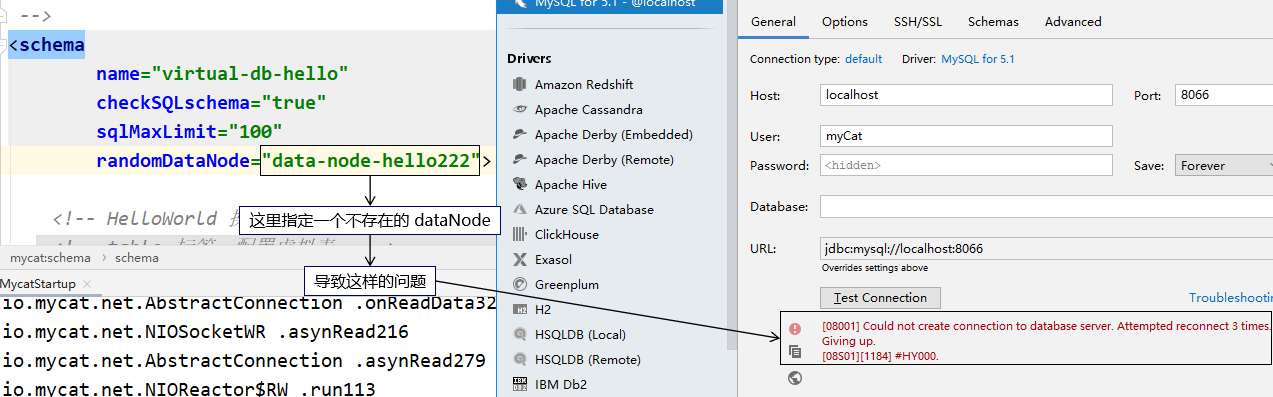
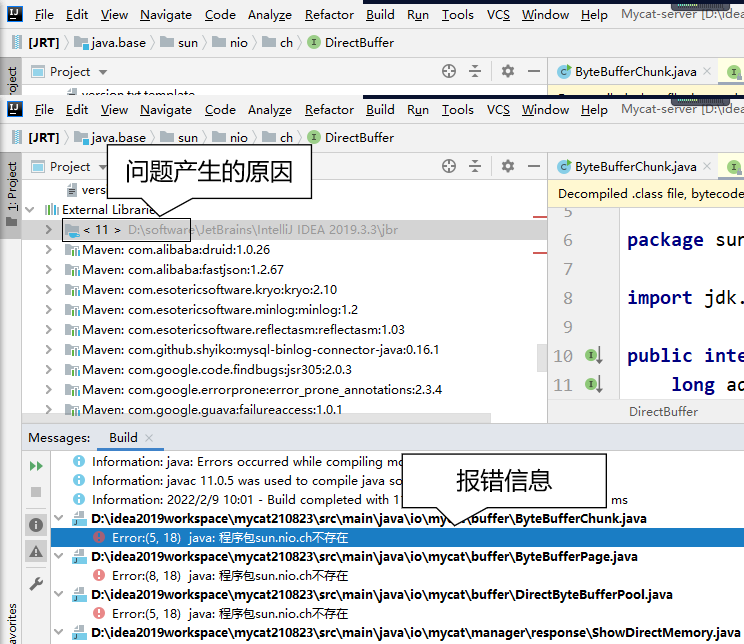
7、两个坑 ①第一个 如果 schema 标签的配置是从官方提供的配置中复制过来的,那么可能会带有 randomDataNode 属性,此时会有下面问题:
如果尝试连接 MyCat 时,没有指定一个具体的数据库名称,MyCat 会访问 randomDataNode 属性指定的数据节点。而如果这个数据节点不存在,那么就会访问失败。
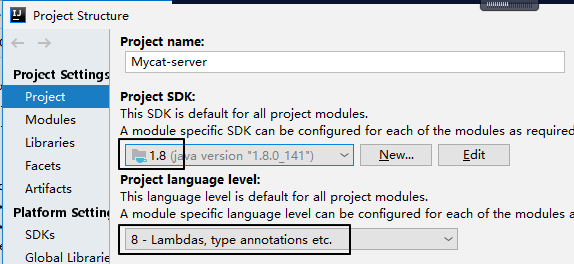
②第二个
调整 JDK 版本操作如下:
第三节 数据分片 1、数据分片概念 从虚拟库、虚拟表看到的数据,逻辑上是一个整体。而实际上数据的物理存储是分散在不同物理库、物理表中。每个实际的物理表可以看成是一个数据分片。
数据进入数据库时,经过不同拆分规则 的分流进入了不同的数据分片。我们对拆分规则有两点期望:
数据存储的过程中:执行 insert 语句后将数据准确插入到对应分片
数据提取的过程中:能够准确的从指定分片查询到我们需要的数据
2、数据分片的具体算法 [取模分片](# ①取模分片)
[全局 id 分片](# ②全局 id 分片)
[枚举分片](# ③枚举分片)
[固定 hash 分片](# ④固定 hash 分片)
[固定范围分片](# ⑤固定范围分片)
[取模范围分片](# ⑥取模范围分片)
[字符串 hash 分片](# ⑦字符串 hash 分片)
[时间分片](# ⑧时间分片)
[一致性 hash 分片](# ⑨一致性 hash 分片)
第四节 跨库 join 概念:A 表和 B 表做关联查询,但是 A 表和 B 表不在同一个数据库中。
1、全局表 系统中基本都会存在数据字典信息,如数据分类信息、项目的配置信息等。这些字典数据最大的特点就是数据量不大并且很少会被改变。同时绝大多数的业务场景都会涉及到字典表的操作。 因此为了避免频繁的跨库join操作,结合冗余数据思想,可以考虑把这些字典信息在每一个分库中都存在一份。
mycat在进行join操作时,当业务表与全局表进行聚合会优先选择相同分片的全局表,从而避免跨库join操作。在进行数据插入时,会把数据同时插入到所有分片的全局表中。
修改 schema.xml
1 <table name ="tb_global" dataNode ="dn142,dn145" primaryKey ="global_id" type ="global" />
2、ER表 ER 表也是一种为了避免跨库join的手段,在业务开发时,经常会使用到主从表关系的查询,如商品表与商品详情表。
ER 表的出现就是为了让有关系的表数据存储于同一个分片中,从而避免跨库 join 的出现。
修改 schema.xml
1 2 3 <table name ="tb_goods" dataNode ="dn129,dn130" primaryKey ="goods_id" rule ="sharding-by-murmur-goods" > <childTable name ="tb_goods_detail" primaryKey ="goods_detail_id" joinKey ="goods_id" parentKey ="goods_id" > </childTable > </table >
再次添加 goods 数据的时候,有关系的表数据存储于同一个分片中
附:分片算法 ①取模分片 [点击返回](# 2、数据分片的具体算法)
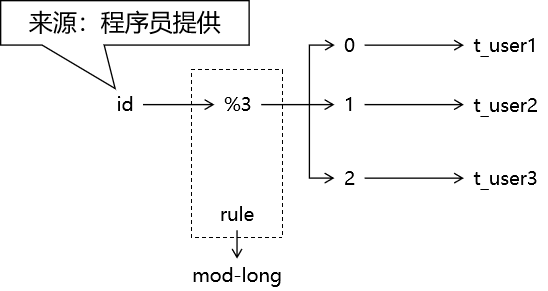
1、理解 根据 id 值进行模运算,然后根据取模的计算结果决定数据分流后存入的目标物理表。这里涉及到的用于取模计算的数据库表字段值,不能指望由数据库自增 来得到——因为这个数据是在决定分流到哪个物理表时用到的,此时还没有执行 insert 语句。所以这个数据必须由程序员指定,在 Java 代码中生成 。
2、操作 ①创建用于测试的物理表 1 2 3 CREATE TABLE `db_hr`.`t_emp1` ( `emp_id` INT NOT NULL AUTO_INCREMENT, `emp_name` CHAR (100 ), PRIMARY KEY (`emp_id`) ); CREATE TABLE `db_hr`.`t_emp2` ( `emp_id` INT NOT NULL AUTO_INCREMENT, `emp_name` CHAR (100 ), PRIMARY KEY (`emp_id`) ); CREATE TABLE `db_hr`.`t_emp3` ( `emp_id` INT NOT NULL AUTO_INCREMENT, `emp_name` CHAR (100 ), PRIMARY KEY (`emp_id`) );
②配置 subTables 属性
所在位置:schema.xml 配置文件中 schema 标签的子标签 table 的 subTables 属性。
属性值设置方式:
单个值:t_user
多个值:
将多个物理表名称用逗号隔开:t_user1,t_user2,t_user3
使用正则表达式格式指定数值区间:t_user$1-5
将多个用区间表示的物理表名称用逗号隔开:t_user$1-5,t_user$7-10
③配置拆分规则
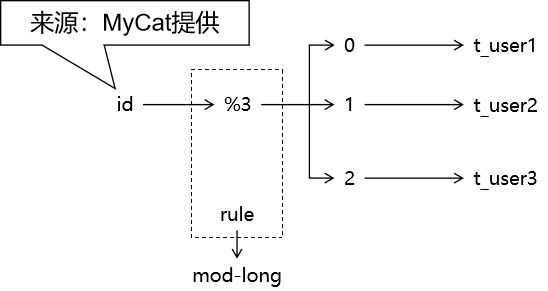
在 table 标签中通过 rule 属性指定规则名称即可。当前取模分片的名称是 mod-lang,这些规则名称是在 rule.xml 中定义的。
1 2 3 4 5 6 7 8 9 10 11 <table name ="virtual_t_emp" primaryKey ="emp_id" dataNode ="data-node-hello" autoIncrement ="true" fetchStoreNodeByJdbc ="true" subTables ="t_emp$1-3" rule ="mod-long" />
④重启 MyCat MyCat 配置文件修改后重启 MyCat 程序才能够生效。
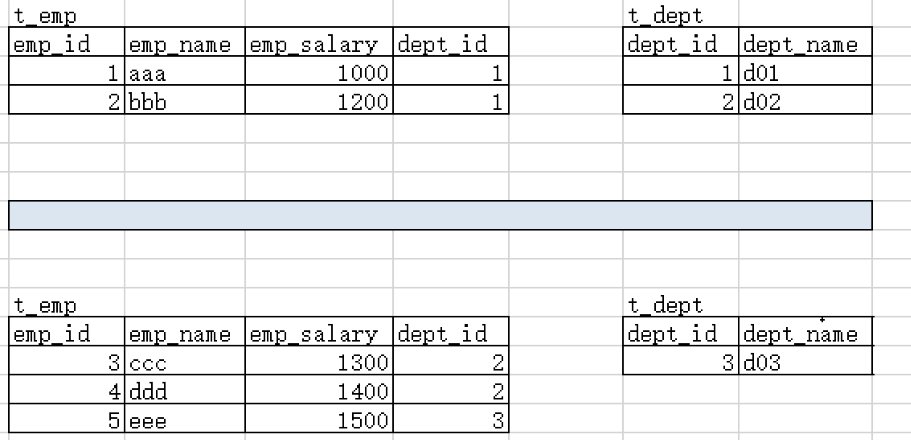
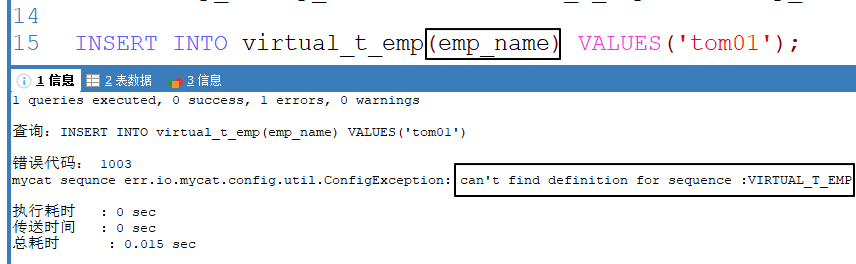
3、测试 ①数据存储操作 1 2 3 4 5 INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES (1 , 'tom01' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES (2 , 'tom02' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES (3 , 'tom03' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES (4 , 'tom04' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES (5 , 'tom05' );
数据插入后,请打开物理表查看是否分流到了三个物理表。
t_emp1
emp_id emp_name
3 tom03
t_emp2
emp_id emp_name
1 tom01
t_emp3
emp_id emp_name
2 tom02
②数据查询操作 1 SELECT emp_id,emp_name FROM virtual_t_emp WHERE emp_id= 4 ;
效果:
emp_id emp_name
4、注意 如果在 insert 语句中没有指定 emp_id 字段,则有下面的报错:
②全局 id 分片 [点击返回](# 2、数据分片的具体算法)
1、理解 全局 id 分片和上面的取模分片就一个区别:id 的来源不同。
取模分片:由程序员提供 id 值。
全局 id 分片:由 MyCat 提供 id 值。
具体来说,MyCat 提供 id 值有下面这些办法:
基于本地文件
基于数据库
基于 zookeeper
基于时间戳
2、操作 ①基于本地文件 第一步:配置 sequence_conf.properties 文件位置:
配置内容:
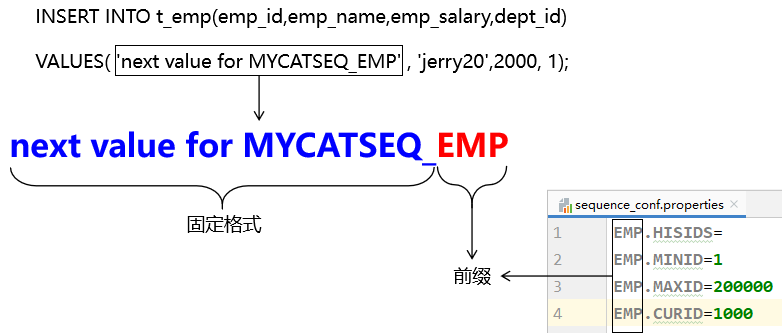
1 2 3 4 5 6 7 8 9 10 11 USER.HISIDS =USER.MINID =1 USER.MAXID =200000 USER.CURID =1000
配置中属性名前缀的作用:
第二步:配置 server.xml 指定全局 id 分片具体使用的 id 生成方式。
1 2 3 4 5 6 7 8 <property name ="sequenceHandlerType" > 0</property >
第三步:测试 别忘记重启 MyCat。
1 2 3 4 5 INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP' , 'jerry01' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP' , 'jerry02' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP' , 'jerry03' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP' , 'jerry04' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP' , 'jerry05' );
②基于数据库 第一步:在物理库建表 使用 MyCat 提供的一个 SQL 文件:
执行的效果:
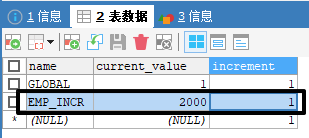
第二步:在 MYCAT_SEQUENCE 表中增加一条记录
第三步:配置 sequence_db_conf.properties 文件位置:
配置内容:
1 EMP_INCR =data-node-hello
属性名和其他配置的关系:
第四步:配置 server.xml 1 2 3 4 <property name ="sequenceHandlerType" > 1</property >
第五步:重启 MyCat 略。
第六步:测试 1 2 3 4 5 6 7 8 9 USE virtual- db- hello;INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP_INCR' , 'kate01' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP_INCR' , 'kate02' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP_INCR' , 'kate03' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP_INCR' , 'kate04' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_EMP_INCR' , 'kate05' );SELECT emp_id,emp_name FROM virtual_t_emp;
③基于时间戳 第一步:配置 server.xml 1 2 3 4 5 <property name ="sequenceHandlerType" > 2</property >
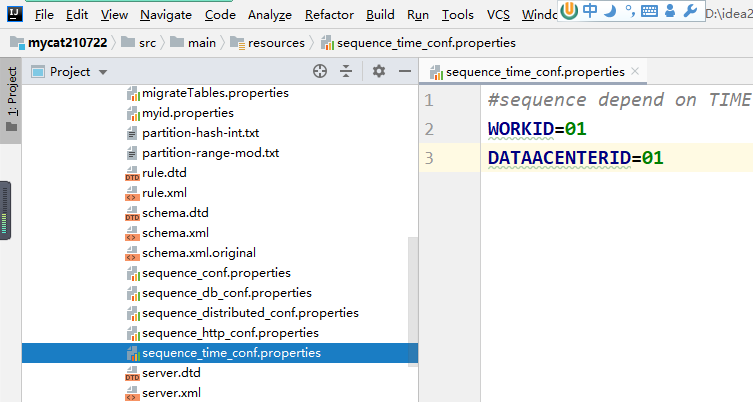
第二步:配置 sequence_time_conf.properties WORKID 与 DATAACENTERID 都是 0-31 任意整数。多 mycat 节点下,每个节点的 WORKID、DATAACENTERID 不能重复,组成唯一标识,总共支持 32*32=1024 种组合。
第三步:修改物理表 emp_id 字段宽度 基于时间戳的方式将使用时间戳数值作为 emp_id 值,必须使用 bigint 类型。
第四步:重启 MyCat 略。
第五步:测试 next value for MYCATSEQ_ 后面可以随便写。
1 2 3 4 5 6 7 8 9 USE virtual- db- hello;INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_FOO' , 'BOB01' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_FOO' , 'BOB02' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_FOO' , 'BOB03' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_FOO' , 'BOB04' );INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES ('next value for MYCATSEQ_FOO' , 'BOB05' );SELECT emp_id,emp_name FROM virtual_t_emp;
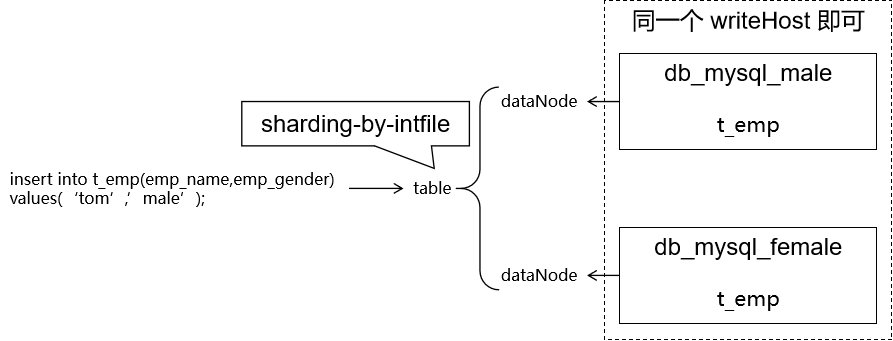
③枚举分片 [点击返回](# 2、数据分片的具体算法)
1、理解
2、操作 第一步:创建数据库和表 在物理库所在的服务器上执行下面的 SQL 语句:
1 2 3 4 CREATE DATABASE `db_hr_male`;CREATE DATABASE `db_hr_female`; CREATE TABLE `db_hr_female`.`t_emp` ( `emp_id` INT NOT NULL AUTO_INCREMENT, `emp_name` CHAR (100 ), `emp_gender` CHAR (100 ), PRIMARY KEY (`emp_id`) );CREATE TABLE `db_hr_male`.`t_emp` ( `emp_id` INT NOT NULL AUTO_INCREMENT, `emp_name` CHAR (100 ), `emp_gender` CHAR (100 ), PRIMARY KEY (`emp_id`) );
第二步:创建新的 dataNode 在 schema.xml 配置文件中增加配置:
1 2 <dataNode name ="data-node-male" dataHost ="virtual-host-hello" database ="db_hr_male" /> <dataNode name ="data-node-female" dataHost ="virtual-host-hello" database ="db_hr_female" />
第三步:配置 table 标签 在 schema.xml 配置文件中修改配置:
1 2 3 4 5 6 7 8 9 10 11 12 <table name ="t_emp" primaryKey ="emp_id" dataNode ="data-node-male,data-node-female" autoIncrement ="true" fetchStoreNodeByJdbc ="true" rule ="sharding-by-intfile" />
第四步:配置 rule.xml
1 2 3 4 5 6 7 8 9 <tableRule name ="sharding-by-intfile" > <rule > <columns > emp_gender</columns > <algorithm > hash-int</algorithm > </rule > </tableRule >
1 2 3 4 5 6 7 8 9 10 11 12 <function name ="hash-int" class ="io.mycat.route.function.PartitionByFileMap" > <property name ="mapFile" > partition-hash-int.txt</property > <property name ="type" > 1</property > <property name ="defaultNode" > 0</property > </function >
第五步:配置 partition-hash-int.txt 1 2 3 4 5 #代表第一个datanode
3、测试 1 2 3 4 USE virtualDB;INSERT INTO t_emp(emp_id, emp_name,emp_gender) VALUES (1 , 'tom' ,'male' );INSERT INTO t_emp(emp_id, emp_name,emp_gender) VALUES (2 , 'kate' ,'female' );
4、注意点
table 标签中不写 subTables 属性,原因是对照枚举规则之后,不同的数据进入了不同数据库中。在各自数据库中的表名是相同的。
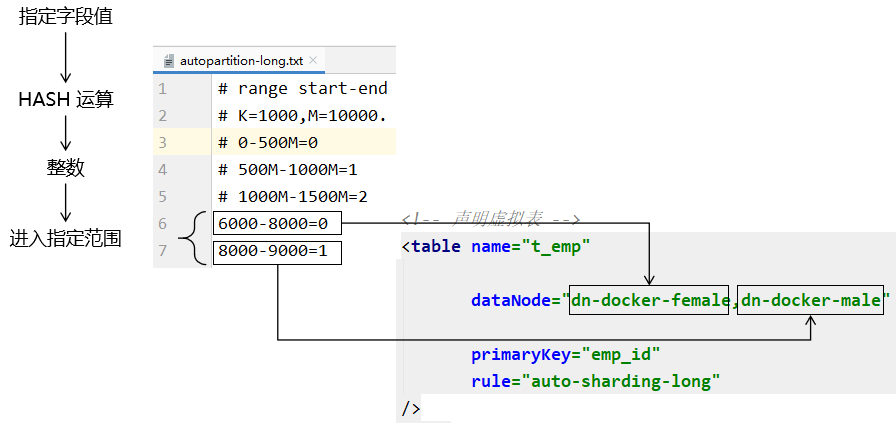
在 partition-hash-int.txt 文件中,0 和 1 这些值表示序号,这个序号对应 table 标签中 dataNode 属性值中 dataNode 名称的顺序。比如:dataNode=”dn-docker-female,dn-docker-male” 这个例子中,dn-docker-female 的序号是 0,dn-docker-male 的序号是 1。
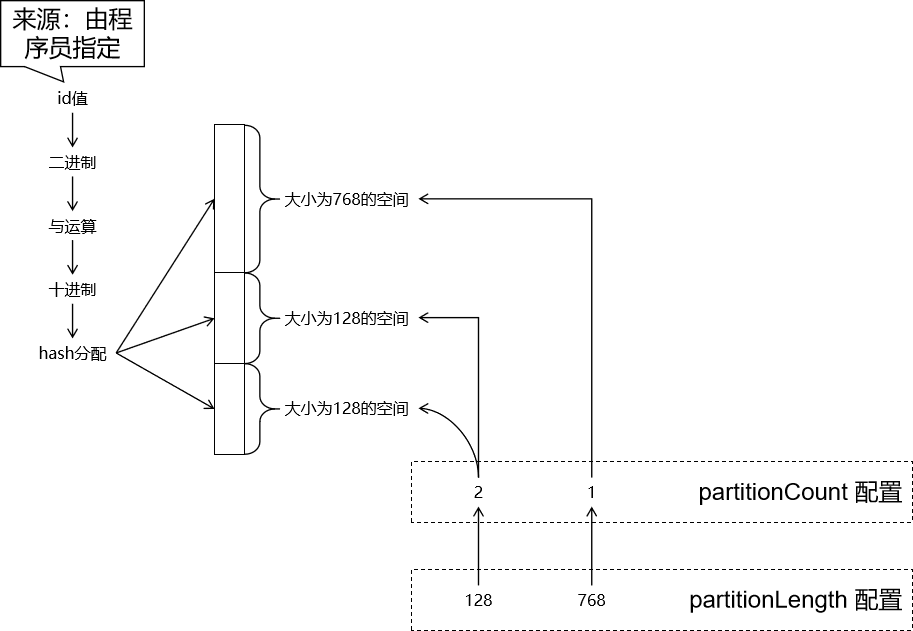
④固定 hash 分片 [点击返回](# 2、数据分片的具体算法)
1、理解
2、操作 第一步:配置 schema.xml 1 2 3 4 5 6 7 8 9 <table name ="t_emp" primaryKey ="emp_id" dataNode ="data-node-male,data-node-female" autoIncrement ="true" fetchStoreNodeByJdbc ="true" rule ="partition-by-fixed-hash" />
第二步:配置 rule.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <tableRule name ="partition-by-fixed-hash" > <rule > <columns > emp_id</columns > <algorithm > partition-by-fixed-hash</algorithm > </rule > </tableRule > <function name ="partition-by-fixed-hash" class ="io.mycat.route.function.PartitionByLong" > <property name ="partitionCount" > 1,1</property > <property name ="partitionLength" > 256,768</property > </function >
3、测试 1 2 3 4 5 6 7 USE virtual- db- hello;INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (50 ,'harry07' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (80 ,'harry08' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (120 ,'harry09' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (360 ,'rose05' ,'female' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (1780 ,'rose06' ,'female' );
⑤固定范围分片 [点击返回](# 2、数据分片的具体算法)
1、理解
2、操作 ①配置 schema.xml 1 2 3 4 5 6 7 8 9 <table name ="t_emp" primaryKey ="emp_id" dataNode ="data-node-male,data-node-female" autoIncrement ="true" fetchStoreNodeByJdbc ="true" rule ="auto-sharding-long" />
②配置 rule.xml 1 2 3 4 5 6 7 <tableRule name ="auto-sharding-long" > <rule > <columns > emp_id</columns > <algorithm > rang-long</algorithm > </rule > </tableRule >
③配置 autopartition-long.txt
1 2 3 4 5 6 7 8 # range start-end ,data node index
3、测试 1 2 3 4 5 6 7 8 9 USE virtual- db- hello;INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (2 ,'jack13' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (4 ,'jack14' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (6 ,'jack15' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (35 ,'rose09' ,'female' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (44 ,'rose10' ,'female' );SELECT emp_id,emp_name,emp_gender FROM t_emp;
⑥取模范围分片 [点击返回](# 2、数据分片的具体算法)
1、理解 取模后,根据范围决定数据节点。
2、操作 ①配置 schema.xml 指定分片规则:sharding-by-partition
②配置 rule.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <tableRule name ="sharding-by-partition" > <rule > <columns > emp_id</columns > <algorithm > sharding-by-partition</algorithm > </rule > </tableRule > <function name ="sharding-by-partition" class ="io.mycat.route.function.PartitionByPattern" > <property name ="patternValue" > 256</property > <property name ="defaultNode" > 0</property > <property name ="mapFile" > partition-pattern.txt</property > </function >
③配置 partition-pattern.txt 这个文件没有,需要我们自己建:
1 2 3 #0-128表示id%256后的数据范围。
3、测试 1 2 3 4 USE virtual- db- hello;INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (90 ,'peter01' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (150 ,'peter02' ,'male' );
⑦字符串 hash 分片 [点击返回](# 2、数据分片的具体算法)
1、理解 在业务场景下,有时可能会根据某个分片字段的前几个值来进行取模。如地址信息只取省份、姓名只取前一个字的姓等。此时则可以使用该种方式。
其工作方式与取模范围分片类似,该分片方式支持数值、符号、字母取模。
执行流程大致是:字符串截取→hash操作→取模→根据指定范围选择 DataNode
2、操作 [1]配置 schema.xml 指定分片规则:sharding-by-string-hash
[2]配置 rule.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <tableRule name ="sharding-by-string-hash" > <rule > <columns > emp_name</columns > <algorithm > sharding-by-string-hash-function</algorithm > </rule > </tableRule > <function name ="sharding-by-string-hash-function" class ="io.mycat.route.function.PartitionByPrefixPattern" > <property name ="patternValue" > 256</property > <property name ="prefixLength" > 1</property > <property name ="mapFile" > partition-pattern-string-hash.txt</property > </function >
[3]配置 partition-pattern-string-hash.txt 3、测试 1 2 3 4 USE virtual- db- hello;INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (88 ,'ccccccc' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (99 ,'uvwxyz' ,'male' );
⑧时间分片 [点击返回](# 2、数据分片的具体算法)
1、理解 根据时间、日期信息分片。
2、操作 ①修改数据库表 给 t_emp 表增加 emp_birthday 字段。
1 2 ALTER TABLE `db_hr_male`.`t_emp` ADD COLUMN `emp_birthday` CHAR (100 ) NULL AFTER `emp_gender`;ALTER TABLE `db_hr_female`.`t_emp` ADD COLUMN `emp_birthday` CHAR (100 ) NULL AFTER `emp_gender`;
②配置 schema.xml 指定拆分规则:sharding-by-date
③配置 rule.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <tableRule name ="sharding-by-date" > <rule > <columns > emp_birthday</columns > <algorithm > partbyday</algorithm > </rule > </tableRule > <function name ="partbyday" class ="io.mycat.route.function.PartitionByDate" > <property name ="dateFormat" > yyyy-MM-dd</property > <property name ="sNaturalDay" > 0</property > <property name ="sBeginDate" > 2014-06-01</property > <property name ="sEndDate" > 2014-06-30</property > <property name ="sPartionDay" > 15</property > </function >
3、测试 1 2 3 4 USE virtual- db- hello;INSERT INTO t_emp(emp_id,emp_birthday) VALUES (666 , '2014-06-10' );INSERT INTO t_emp(emp_id,emp_birthday) VALUES (777 , '2014-06-25' );
⑨一致性 hash 分片 [点击返回](# 2、数据分片的具体算法)
1、理解 ①目的 最大限度的让数据均匀分布
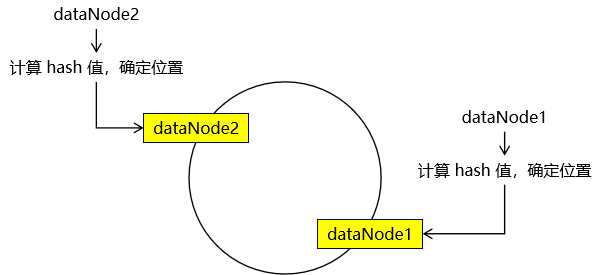
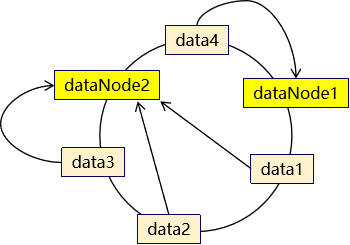
②原理 一致性 hash 算法引入了 hash 环的概念。环的大小是 0~2^32-1。首先通过 crc16 算法计算出数据节点在 hash 环中的位置。
当存储数据时,也会采用同样的算法,计算出数据key的hash值,映射到hash环上。
然后从数据映射的位置开始,以顺时针的方式找出距离最近的数据节点,接着将数据存入到该节点中。
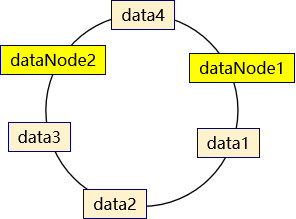
此时可以发现,数据并没有达到预期的数据均匀,可以发现如果两个数据节点在环上的距离,决定有大量数据存入了dataNode2,而仅有少量数据存入dataNode1。
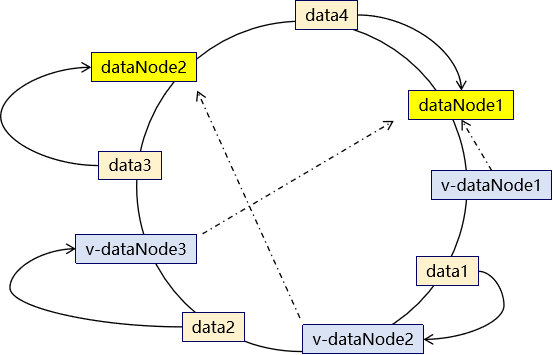
为了解决数据不均匀的问题,在mycat中可以设置虚拟数据映射节点 。同时这些虚拟节点会映射到实际数据节点。
数据仍然以顺时针方式寻找数据节点,当找到最近的数据节点无论是实际还是虚拟,都会进行存储,如果是虚拟数据节点的话,最终会将数据保存到实际数据节点中。 从而尽量的使数据均匀分布。
2、操作 ①配置 schema.xml 指定拆分规则:sharding-by-murmur
②配置 rule.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <tableRule name ="sharding-by-murmur" > <rule > <columns > emp_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule > <function name ="murmur" class ="io.mycat.route.function.PartitionByMurmurHash" > <property name ="seed" > 0</property > <property name ="count" > 2</property > <property name ="virtualBucketTimes" > 160</property > </function >
3、测试 1 2 3 4 USE virtual- db- hello;INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (111 ,'eeeeeeeeeee' ,'male' );INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES (888 ,'ttttttttttt' ,'male' );