MySQL-架构引擎
本文最后更新于:9 天前
MySQL 逻辑架构
1、总述
和其它数据库有所不同,MySQL 的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,『插件式』的『存储引擎架构』将查询和其它的系统任务以及数据的存储提取相分离。
这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
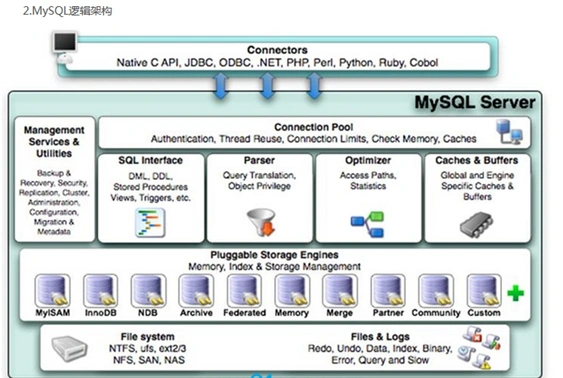
2、连接层
最上层是一些客户端和连接服务,包含本地 sock 通信和大多数基于客户端/服务端工具实现的类似于 TCP/IP 的通信。
主要任务是连接处理、授权认证、及相关的安全方案等。
该层引入了线程池,为通过认证、安全接入的客户端提供线程处理任务。
同样在该层上可以实现基于 SSL 的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
3、服务层
第二层架构主要完成大多数的核心服务功能。如 SQL 接口、并完成缓存的查询、SQL 的分析和优化及部分内置函数的执行。
所有跨存储引擎的功能也在这一层实现,如过程、函数等。
在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化:如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。
如果是 select 语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
| 模块名称 | 作用 |
|---|---|
| Management Serveices & Utilities | 系统管理和控制工具 |
| SQL Interface | 接受用户的 SQL 指令,并且返回查询的结果。比如 select from 就是调用SQL Interface |
| Parser | SQL 命令传递到解析器的时候会被解析器验证和解析。 |
| Optimizer | 查询优化器 SQL 语句在查询之前会使用查询优化器对查询进行优化。 例如: select uid,name from user where gender= 1; 查询优化器来决定先投影还是先过滤。 |
| Cache和Buffer | 查询缓存,存储 SELECT 语句以及相应的查询结果集 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。 这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key 缓存,权限缓存等 |
4、引擎层
存储引擎层,存储引擎真正的负责了 MySQL 中数据的存储和提取,服务器通过 API 与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要选取。后面介绍 MyISAM 和 InnoDB。
5、存储层
数据存储层,主要是将数据存储在运行于文件系统上,并完成与存储引擎的交互。
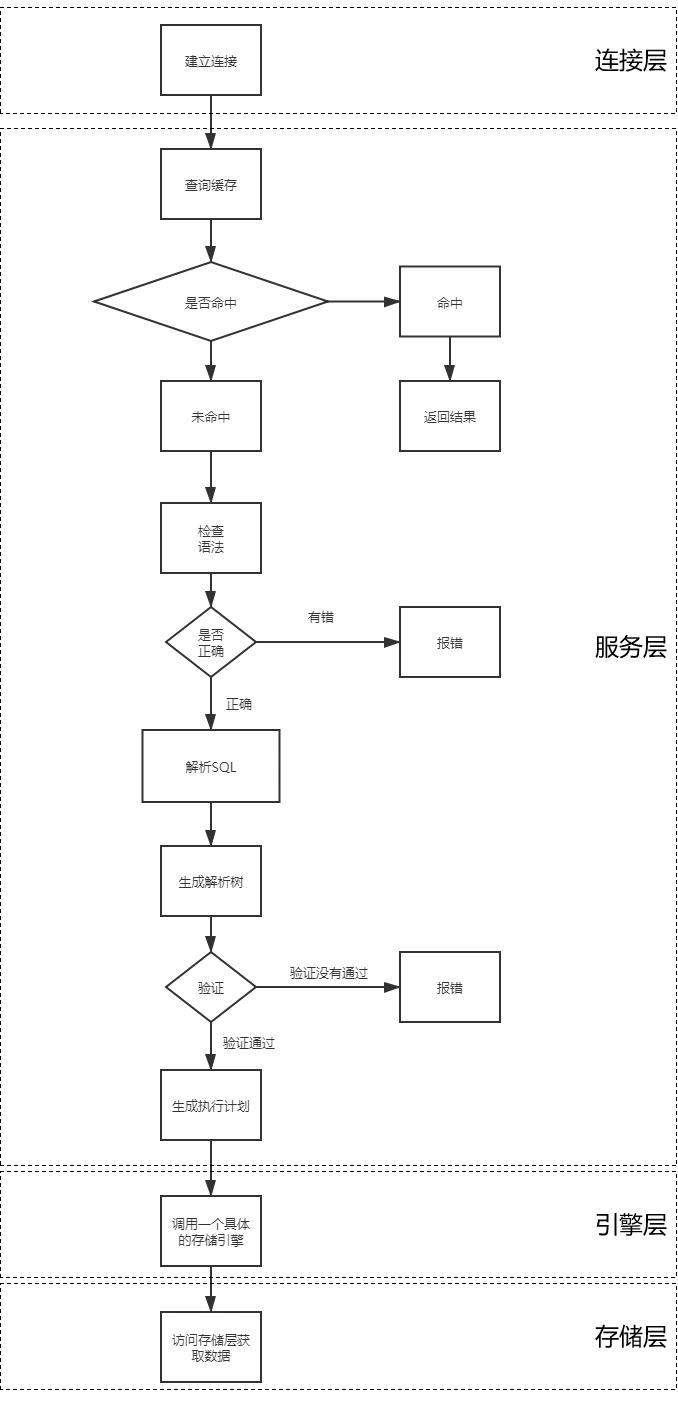
6、工作流程
①建立连接
MySQL 客户端通过协议与 MySQL 服务器建连接,发送查询语句。
②查询缓存
检查查询缓存中是否存在要查询的数据。
命中:直接返回结果。
不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
未命中:解析 SQL 语句。
③语法解析器和预处理
MySQL 首先根据语法规则验证 SQL 语句的语法正确性,然后通过关键字将 SQL 语句进行解析,并生成一棵对应的『解析树』。预处理器则根据一些 MySQL 规则进一步检查解析树是否正确。
④生成执行计划
当解析树被确认为正确,接下来就会由查询优化器将解析树转化成执行计划(profile)。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
⑤按计划执行并获取数据
MySQL 默认使用 B+Tree 索引,并且一个大致方向是:无论怎么调整 SQL,至少在目前来说,MySQL 最多只用到表中的一个索引。
存储引擎
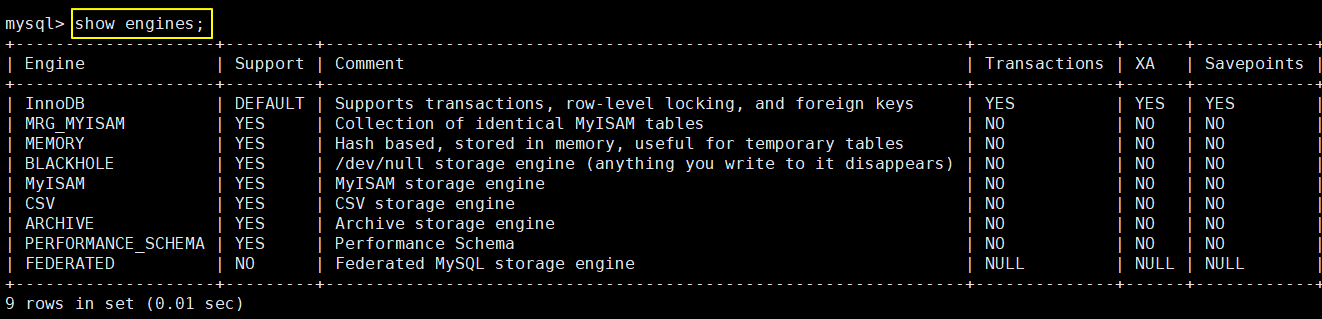
1、查看存储引擎
①查看 MySQL 支持的存储引擎
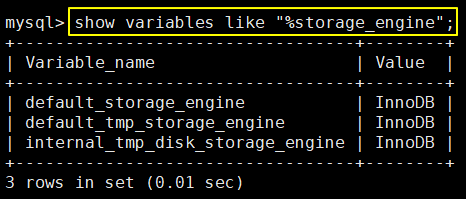
②查看当前默认的存储引擎
2、引擎介绍
①InnoDB
MySQL 从 5.5 版本之后,就开始默认采用 InnoDB 引擎。
TIP
- InnoDB 是 MySQL 的默认事务型引擎。
- InnoDB 被设计用来处理大量的短期(short-lived)事务。可以确保事务的完整提交(Commit)和回滚(Rollback)。
- 如果除了增加和查询外,还需要更新和删除操作,那么应优先选择 InnoDB 存储引擎。
- 除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑 InnoDB 引擎。
②MyISAM
MySQL 在 5.5 版本之前,默认使用 MyISAM 引擎。
TIP
MyISAM 提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等。但 MyISAM 不支持事务和行级锁,有一个毫无疑问的缺陷就是崩溃后无法安全恢复。
- 数据文件结构:
- .frm 存储定义表
- .MYD 存储数据
- .MYI 存储索引
WARNING
注意:
- 静态表字段都是非变长字段,存储占用空间比动态表多。
- 非变长字段存储数据时会按照列宽补足空格,但在访问时候并不会得到这些空格。
- 如果存储数据本身后面有空格,查询时也会被去掉。
- 如果存储数据本身前面有空格,查询时不会被去掉。
- 在没有 where 条件情况下统计表 count(*) 数量,不需要全表扫描,而是直接获取保存好的值。
③Archive
- Archive 档案存储引擎只支持 INSERT 和 SELECT 操作,在 MySQL 5.1 之前不支持索引。
- Archive 表适合日志和数据采集(档案)类应用。
- 根据英文的测试结论来看,Archive 表比 MyISAM 表要小大约 75%,比支持事务处理的 InnoDB 表小大约83%。
④Blackhole
- Blackhole 引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存。
- 但服务器会记录 Blackhole 表的日志,所以可以用于复制数据到备库,或者简单地记录到日志。但这种应用方式会碰到很多问题,因此并不推荐。
⑤CSV
- CSV 引擎可以将普通的 CSV 文件作为 MySQL 的表来处理,但不支持索引。
- CSV 引擎可以作为一种数据交换的机制,非常有用。
- CSV 存储的数据直接可以在操作系统里,用文本编辑器,或者 Excel 读取。
⑥Memory
- 如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用 Memory 表是非常有用。
- Memory 表至少比 MyISAM 表要快一个数量级。
TIP
- 数量级:两位数比个位数高一个数量级;四位数比三位数高一个数量级。
- 量级:一个体系在所有维度综合之后,超越另一个体系,就是量级的差距。比如:信息化社会的经济水平比工业化社会的经济水平高一个量级;工业化社会的经济水平比农业社会的经济水平高一个量级。
⑦Federated
Federated 引擎是访问其他 MySQL 服务器的一个代理,尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的。
3、巅峰对决
下面我们将最常见的 InnoDB 和 MyISAM 两个引擎详细对比一下:
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 支持表锁 即使操作一条记录也会锁住整个表, 不适合高并发操作 | 支持行锁 操作时只锁某一行,不对其它行有影响, 适合高并发操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据, 对内存要求较高, 而且内存大小对性能有决定性的影响 |
| 系统提供预创建数据库表 给用户使用 | 是 | 否 |
| 关注点 | 性能:节省资源、消耗少、简单业务 | 事务:并发写、事务、更大资源 |
| 默认安装 | 是 | 是 |
| 默认使用 | 否 | 是 |
MySQL 索引语法
1、概念介绍
| 索引类型 | 索引特点 |
|---|---|
| 单列索引 | 即一个索引是只根据一个字段创建的,里面只包含单个列, 一个表可以有多个单值索引(也叫单列索引) |
| 联合索引 | 即一个索引包含多个列 |
| 唯一索引 | 索引列的值必须唯一,但允许有空值,空值可以有多个 |
| 主键索引 | 设定为主键后数据库会自动建立索引,InnoDB 为聚簇索引 |
TIP
当我们平时谈到『主键』时,这个概念包含三个方面的具体含义:
- 主键字段和这个字段中具体的值
- 主键约束
- 主键索引
2、索引操作语法
相关语法可以参考 W3CSchool 教程:https://www.w3school.com.cn/sql/sql_create_index.asp
①准备工作
1 | |
②创建单值索引
1 | |
③创建唯一索引
1 | |
④联合索引
1 | |
索引创建好可以如下图所示方式查看:

⑤删除索引
1 | |
3、最佳实践
①需要创建索引的情况
主键自动建立唯一索引
频繁作为查询条件的字段应该创建索引,也就是经常出现在 where 子句中的字段,尤其是数据表大的时候
关联查询
- 不要涉及 3 张以上的表
- 小表驱动大表,给大表的关联字段创建索引
- 尽量先用 where 条件过滤数据
- 关联字段在各个表中类型要一致
单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
说明:同样是 A、B、C 三个字段,是分别创建三个索引,还是创建一个组合索引?
答案:此时通常来说我们更倾向于创建组合索引。因为基本上来说不管怎么优化,MySQL 里一条 SQL 语句中只有一个字段的索引能够生效。所以我们建立组合索引并参照最左原则能够让更多的索引起到作用。
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
查询中统计或者分组的字段
②下列情况创建索引效果更好
- 字段的数值有唯一性限制
- 类型小的字段
③不要创建索引的情况
- MySQL 中,一张数据库表中记录数量小于 300 万条时,即使创建索引也不会让搜索速度有明显提升。
- 经常增删改的表,建立索引提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件,重新排布索引,这个操作需要对索引表做全表扫描。不仅索引表的全表扫描操作本身非常耗时,而且索引重新排布时不可用,此时执行查询操作没有索引可用,还是要回到原始数据库表做全表扫描。
- where 条件里用不到的字段
- 数据重复,过滤性不好的字段
- 无法排序的字段
- 不要创建冗余或重复的索引
④结论
索引并不是无条件创建、越多越好,而是要根据实际情况恰到好处的创建。不再使用或很少使用的索引要删除掉。